#plugin parse error
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 27% of US Tumblr users had an annual household income of over $100,000.
Text
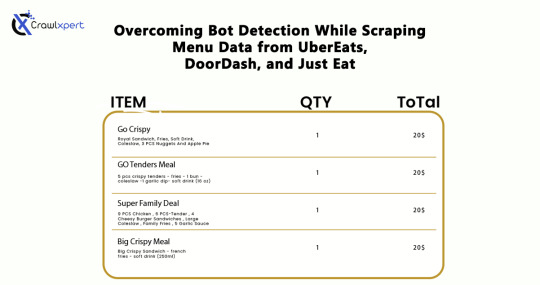
Overcoming Bot Detection While Scraping Menu Data from UberEats, DoorDash, and Just Eat
Introduction
In industries where menu data collection is concerned, web scraping would serve very well for us: UberEats, DoorDash, and Just Eat are the some examples. However, websites use very elaborate bot detection methods to stop the automated collection of information. In overcoming these factors, advanced scraping techniques would apply with huge relevance: rotating IPs, headless browsing, CAPTCHA solving, and AI methodology.
This guide will discuss how to bypass bot detection during menu data scraping and all challenges with the best practices for seamless and ethical data extraction.
Understanding Bot Detection on Food Delivery Platforms
1. Common Bot Detection Techniques
Food delivery platforms use various methods to block automated scrapers:
IP Blocking – Detects repeated requests from the same IP and blocks access.
User-Agent Tracking – Identifies and blocks non-human browsing patterns.
CAPTCHA Challenges – Requires solving puzzles to verify human presence.
JavaScript Challenges – Uses scripts to detect bots attempting to load pages without interaction.
Behavioral Analysis – Tracks mouse movements, scrolling, and keystrokes to differentiate bots from humans.
2. Rate Limiting and Request Patterns
Platforms monitor the frequency of requests coming from a specific IP or user session. If a scraper makes too many requests within a short time frame, it triggers rate limiting, causing the scraper to receive 403 Forbidden or 429 Too Many Requests errors.
3. Device Fingerprinting
Many websites use sophisticated techniques to detect unique attributes of a browser and device. This includes screen resolution, installed plugins, and system fonts. If a scraper runs on a known bot signature, it gets flagged.
Techniques to Overcome Bot Detection
1. IP Rotation and Proxy Management
Using a pool of rotating IPs helps avoid detection and blocking.
Use residential proxies instead of data center IPs.
Rotate IPs with each request to simulate different users.
Leverage proxy providers like Bright Data, ScraperAPI, and Smartproxy.
Implement session-based IP switching to maintain persistence.
2. Mimic Human Browsing Behavior
To appear more human-like, scrapers should:
Introduce random time delays between requests.
Use headless browsers like Puppeteer or Playwright to simulate real interactions.
Scroll pages and click elements programmatically to mimic real user behavior.
Randomize mouse movements and keyboard inputs.
Avoid loading pages at robotic speeds; introduce a natural browsing flow.
3. Bypassing CAPTCHA Challenges
Implement automated CAPTCHA-solving services like 2Captcha, Anti-Captcha, or DeathByCaptcha.
Use machine learning models to recognize and solve simple CAPTCHAs.
Avoid triggering CAPTCHAs by limiting request frequency and mimicking human navigation.
Employ AI-based CAPTCHA solvers that use pattern recognition to bypass common challenges.
4. Handling JavaScript-Rendered Content
Use Selenium, Puppeteer, or Playwright to interact with JavaScript-heavy pages.
Extract data directly from network requests instead of parsing the rendered HTML.
Load pages dynamically to prevent detection through static scrapers.
Emulate browser interactions by executing JavaScript code as real users would.
Cache previously scraped data to minimize redundant requests.
5. API-Based Extraction (Where Possible)
Some food delivery platforms offer APIs to access menu data. If available:
Check the official API documentation for pricing and access conditions.
Use API keys responsibly and avoid exceeding rate limits.
Combine API-based and web scraping approaches for optimal efficiency.
6. Using AI for Advanced Scraping
Machine learning models can help scrapers adapt to evolving anti-bot measures by:
Detecting and avoiding honeypots designed to catch bots.
Using natural language processing (NLP) to extract and categorize menu data efficiently.
Predicting changes in website structure to maintain scraper functionality.
Best Practices for Ethical Web Scraping
While overcoming bot detection is necessary, ethical web scraping ensures compliance with legal and industry standards:
Respect Robots.txt – Follow site policies on data access.
Avoid Excessive Requests – Scrape efficiently to prevent server overload.
Use Data Responsibly – Extracted data should be used for legitimate business insights only.
Maintain Transparency – If possible, obtain permission before scraping sensitive data.
Ensure Data Accuracy – Validate extracted data to avoid misleading information.
Challenges and Solutions for Long-Term Scraping Success
1. Managing Dynamic Website Changes
Food delivery platforms frequently update their website structure. Strategies to mitigate this include:
Monitoring website changes with automated UI tests.
Using XPath selectors instead of fixed HTML elements.
Implementing fallback scraping techniques in case of site modifications.
2. Avoiding Account Bans and Detection
If scraping requires logging into an account, prevent bans by:
Using multiple accounts to distribute request loads.
Avoiding excessive logins from the same device or IP.
Randomizing browser fingerprints using tools like Multilogin.
3. Cost Considerations for Large-Scale Scraping
Maintaining an advanced scraping infrastructure can be expensive. Cost optimization strategies include:
Using serverless functions to run scrapers on demand.
Choosing affordable proxy providers that balance performance and cost.
Optimizing scraper efficiency to reduce unnecessary requests.
Future Trends in Web Scraping for Food Delivery Data
As web scraping evolves, new advancements are shaping how businesses collect menu data:
AI-Powered Scrapers – Machine learning models will adapt more efficiently to website changes.
Increased Use of APIs – Companies will increasingly rely on API access instead of web scraping.
Stronger Anti-Scraping Technologies – Platforms will develop more advanced security measures.
Ethical Scraping Frameworks – Legal guidelines and compliance measures will become more standardized.
Conclusion
Uber Eats, DoorDash, and Just Eat represent great challenges for menu data scraping, mainly due to their advanced bot detection systems. Nevertheless, if IP rotation, headless browsing, solutions to CAPTCHA, and JavaScript execution methodologies, augmented with AI tools, are applied, businesses can easily scrape valuable data without incurring the wrath of anti-scraping measures.
If you are an automated and reliable web scraper, CrawlXpert is the solution for you, which specializes in tools and services to extract menu data with efficiency while staying legally and ethically compliant. The right techniques, along with updates on recent trends in web scrapping, will keep the food delivery data collection effort successful long into the foreseeable future.
Know More : https://www.crawlxpert.com/blog/scraping-menu-data-from-ubereats-doordash-and-just-eat
#ScrapingMenuDatafromUberEats#ScrapingMenuDatafromDoorDash#ScrapingMenuDatafromJustEat#ScrapingforFoodDeliveryData
0 notes
Text
Global Address Verification API: 245+ Countries Address Database
Operating in a global market requires an address verification solution that supports worldwide address formats and postal regulations. A global address verification API enables businesses to validate addresses from over 245 countries and territories.
What Is a Global Address Verification API?
It’s a software interface that allows developers and systems to send address data for validation, standardization, and correction in real-time or batch mode.
Key Capabilities
Multilingual input and output support
Transliteration and standardization for non-Latin scripts
Validation against international postal authorities
Geolocation enrichment
Why Use It?
Avoid delivery delays and customs issues
Increase international customer satisfaction
Ensure accurate billing and shipping records
Challenges in Global Address Verification
Different address structures per country
Non-standardized postal codes or city names
Language and script variations
Frequent changes in administrative divisions
Global Address Database Coverage
Includes official postal data from:
United States (USPS)
Canada (Canada Post)
United Kingdom (Royal Mail)
Australia (Australia Post)
Germany (Deutsche Post)
Japan Post
And 240+ others
Top Global Address Verification API Providers
Loqate
Melissa Global Address Verification
SmartyStreets International API
Google Maps Places API (for autocomplete and partial validation)
HERE Technologies
How It Works
Input Collection: User enters address via web form or app.
API Call: The address is sent to the global verification API.
Data Processing:
Parsed and matched against local country address rules
Standardized and corrected
Output: Returns validated address, possible corrections, and geolocation data.
Use Cases
Ecommerce platforms shipping worldwide
Subscription box services with international clients
Financial institutions verifying global customer records
Travel agencies handling cross-border bookings
Compliance and Data Privacy
Ensure your API vendor complies with:
GDPR (Europe)
CCPA (California)
PIPEDA (Canada)
Data localization laws (as applicable)
Tips for Choosing the Right API
Evaluate global coverage accuracy
Look for uptime and support availability
Consider ease of integration (RESTful API, SDKs, plugins)
Prioritize scalability and speed
Final Thoughts
Investing in robust global address verification API is essential for businesses operating across borders. Not only does it streamline logistics and reduce errors, but it also builds trust with customers by ensuring reliable communication and delivery.
By implementing these address checking solutions and leveraging modern tools tailored for both local and international use, businesses can dramatically improve operational efficiency, cut costs, and deliver a superior customer experience.
youtube
SITES WE SUPPORT
Validate USPS Address – Wix
1 note
·
View note
Text
The Role of CSS Compressor & Minifier in Web Development
One crucial aspect of optimizing website performance lies in the management of CSS files. These files, responsible for styling web pages, can often become bloated with unnecessary whitespace, comments, and redundant code. This is where CSS compressor and minifier tools come into play, offering developers powerful solutions to streamline their CSS code and improve site loading times.
Understanding CSS Compression and Minification CSS compression and minification are processes aimed at reducing the size of CSS files by removing unnecessary characters and optimizing code structure. While compression focuses on reducing file size by eliminating whitespace, comments, and other non-essential characters, minification goes a step further by shortening variable names and optimizing the code for faster parsing by browsers.
Benefits of CSS Compression and Minification
Improved Website Performance: By reducing the size of CSS files, compression and minification contribute to faster page loading times, resulting in a smoother user experience.
Bandwidth Savings: Smaller CSS files require less bandwidth to download, making them particularly beneficial for users on slower internet connections or mobile devices.
Enhanced SEO: Website speed is a crucial factor in search engine rankings. By optimizing CSS files, developers can improve site performance and potentially boost their SEO rankings. Reduced Maintenance Overhead: Minified CSS files are easier to maintain and update, as they contain fewer lines of code and are less prone to errors.
Choosing the Right CSS Compressor & MinifierWhen selecting a CSS compressor and minifier tool, developers should consider factors such as performance, ease of use, and compatibility with existing workflows. Some popular options include:
Online Tools: Web-based CSS compressors and minifiers offer convenience and accessibility, allowing developers to quickly optimize their CSS code without the need for additional software.
Build Tools: Many build tools, such as Grunt, Gulp, and webpack, include plugins for CSS optimization. These tools can be integrated into automated build processes, streamlining development workflows.
Command-Line Utilities: For developers comfortable with the command line, standalone CSS minification utilities provide a lightweight and efficient solution for optimizing CSS files.
Best Practices for CSS Optimization In addition to using compression and minification Hotspotseo tools, developers can follow these best practices to further optimize their CSS code:
Consolidate and Combine Files: Minimize the number of CSS files by combining them into a single file, reducing the number of HTTP requests required to load the page.
Use CSS Sprites: Combine multiple images into a single image sprite to reduce the number of image requests and improve loading times. Utilize Browser Caching: Leverage browser caching techniques to store CSS files locally, reducing server load and speeding up subsequent page loads.
Conclusion CSS compression and minification play a crucial role in optimizing website performance and enhancing the user experience. By utilizing these tools and following best practices for CSS optimization, developers can create faster, more efficient websites that rank higher in search engine results and provide a seamless browsing experience for visitors. Embracing the power of CSS compression and minification is essential for staying competitive in today's fast-paced digital landscape.
0 notes
Text
Blazor : Will it slay the JavaScript/SPA Frameworks?
It has been a long time since Microsoft allowed support of .NET directly on client-side. The last attempt was with Silverlight which got famous when it launched but due to lack of support from browsers and security concerns it stopped; like what happened to Adobe Flash.

……………………………………………………………………………………………………
What is BLAZOR?
Blazor is an attempt to bring .NET core to the browser directly which allows supported language like C# to run directly on the browser. Blazor allows developing Single Page Application (SPA) very quickly and by using a single language on both server and client.
Blazor allows having features similar to any other SPA framework like Routing, Template, Binding – one or two way, Rendering, etc.
The name comes by combining Browser and MVC Razor i.e Blazor.
How does it work?
It entirely relies on WebAssembly (Wasm). Wasm was developed in 2015, to run high-level language directly on browsers. It is supported by W3C which means it is standard and could be utilized by different platform too. There are runtimes available to run C++ codes on browsers too. Since it is from W3C all latest browsers generally have the support of Wasm.
Blazor runs via Wasm but in-between there needs to be a runtime. Mono Wasm allows required .NET assemblies downloads on browser directly which runs on Mono Wasm Virtual Machine.
What are all advantages of Blazor?
A single roof of programming language to build client and server-side codes.
Wasm is generally faster than JavaScript (JS) because those are binary/compiled code. No need for parsing of scripts.
A typed system, a fewer scope of errors due to same. Razor, model binding, etc.
All sweet features of C# and .NET core: Dependency Injection (DI), delegates/events, etc.
Visual Studio Integrated Development Environment (IDE) to allow a rich experience to develop applications quickly with many provided inbuilt or plug-in supported features.
A fallback approach to enable Blazor to run if Wasm is not available to any browser. No issue of Garbage collection like all .NET platform, Mono Wasm supports it too.
Limitations of Blazor
Still is in the development phase, not recommended for production use.
Limited debugging support of Blazor codes since it runs on Wasm.
No way to access DOM elements has to rely on JavaScript for same.
The second biggest, there is not much components/control available in Blazor to have richer User Experience (UX). Like as simple as AutoSuggestion, we have to rely on JavaScript plugin for same.
Demo of Blazor
https://www.youtube.com/watch?v=IGj49kaYPEc The source code used in demo: https://github.com/viku85/BlazorDemo
Conclusion and Future
Blazor is easy to use with minimal effort in comparison to any JS SPA framework available in the market. Since it is on .NET, there is less learning curve for people coming from the .NET environment.
A lot of changes and development is going on with Blazor, many refinements, performance improvements, feature add-ons but still not having a final version to use on production. I believe with the support of controls like Kendo or inbuilt controls in Blazor, application development would be much quicker and feature rich.
We need to wait for the final release (if it happens) and a wide variety of supported controls which may kill JS Frameworks at least in the Microsoft development environment.
……………………………………………………………………………………………………
The views and opinions expressed in this article are those of the author. An avid techie, Vikash enjoys sharing his thoughts on computing and technology in his personal blog. To know more about our company, please click on Mindfire Solutions.
0 notes
Text
How To Do Web Scraping? A Step-By-Step Guide!
As a seasoned web developer, I've witnessed the power of web scraping in extracting valuable data from websites. This technique is invaluable for gathering information for various purposes, from market research to content creation. In this comprehensive guide, I'll walk you through the essential steps of web scraping, equipping you with the knowledge to harness this powerful tool for your projects.
1. Understanding Web Scraping
Web scraping involves the automated extraction of data from websites. It's a technique used to gather information that is not readily available through APIs or downloadable datasets. While immensely powerful, it's crucial to approach web scraping ethically and in compliance with website terms of use.
2. Choosing the Right Tools
Selecting the appropriate tools for web scraping is crucial. Python, with libraries like Beautiful Soup and Requests, is a popular choice due to its simplicity and extensive community support. Other options include Scrapy, Puppeteer (for JavaScript-heavy websites), and various web scraping extensions and plugins.
3. Identifying the Target Website
Start by identifying the website you want to scrape. Analyze its structure, paying attention to the HTML elements that contain the data you're interested in. This will guide you in crafting the right selectors to extract the desired information.
4. Inspecting the HTML Structure
Using your web browser's developer tools, inspect the HTML structure of the target website. This will help you identify the specific tags, classes, or IDs that contain the data you want to extract. These will serve as your "selectors" in the scraping process.
5. Requesting and Parsing the Web Page
Utilize a library like Requests in Python to send an HTTP request to the website. Once you receive the HTML content, use Beautiful Soup to parse it and navigate through the DOM (Document Object Model) to locate and extract the desired data.
6. Handling Pagination and Dynamic Content
If the data you need is spread across multiple pages or involves dynamic content loading, you may need to implement pagination or utilize tools like Selenium or Puppeteer to interact with the website and retrieve all the necessary information.
7. Data Cleaning and Structuring
Upon extraction, the data may require cleaning and structuring. This involves removing any unwanted characters, duplicates, or irrelevant information. Depending on your project, you may also need to format the data into a specific structure or save it in a desired format (e.g., CSV, JSON).
8. Handling Errors and Exceptions
Web scraping is not always straightforward. Websites may have anti-scraping measures in place, or the structure may change over time. Implement error handling and exception management to ensure your scraper can adapt to different scenarios.
9. Respecting Website Terms of Use
It's imperative to scrape websites responsibly and ethically. Be sure to review and comply with the website's terms of use, and consider adding a delay between requests to avoid overloading the server.
10. Testing and Refining Your Scraper
Test your web scraper on various pages of the target website to ensure it consistently extracts the desired data. Iterate and refine your scraper as needed to improve its accuracy and efficiency.
Web scraping is a powerful tool in a developer's arsenal, opening up a world of possibilities for data extraction and analysis. At Future Insights, the best web development company in Bangalore, we follow these exact steps to scrape the websites ethically. By following these steps and continuously honing your skills, you'll be well-equipped to tackle a wide range of web scraping projects.
Remember, practice makes perfect, so don't hesitate to dive in and start scraping!
0 notes
Text
This Week in Rust 466
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tweet us at @ThisWeekInRust or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Foundation
Implementing the Network Time Protocol (NTP) in Rust
Project/Tooling Updates
rust-analyzer changelog #152
IntelliJ Rust Changelog #181
mirrord 3.0 is out!
gix credential and diffing with similar
New release – gtk-rs
Zellij 0.32.0: YAML => KDL, actions through CLI, command panes and a new layout system
RPITs, RPITITs and AFITs and their relationship
Evaluating Build Scripts in the IntelliJ Rust Plugin
Observations/Thoughts
Adding Ada to Rust
Adding a JavaScript interpreter to your Rust project
Rust in the Linux Kernel: Just the Beginning
A deeper look into the GCC Rust front-end
The HTTP crash course nobody asked for
Making Rust attractive for writing GTK applications
Adventures In Cross Compilation
Compiling Brainfuck code - Part 1: A Optimized Interpreter
Rust Embedded Graphics with the MAX7219
Buffers on the edge: Python and Rust · Alex Gaynor
Writing Better Integration Tests with RAII
Contention on multi-threaded regex matching
Rust Walkthroughs
Serde by Example 2: OpenStreetMap
Enums and Pattern Matching in Rust
Creating a minimal RESTful song request API using Rocket
Compiling Rust libraries for Android apps: a deep dive
Inline Crates
Writing a HashMap in Rust without unsafe
A Rust web app with HTML templates
Nine Rules for Creating Procedural Macros in Rust: Practical Lessons from anyinput, a New Macro for Easily Accepting String/Path/Iterator/Array-Like Inputs
[series] Sqlite File Parser Pt 4
MacroKata: Rustlings style exercises for learning macros
Miscellaneous
[video] Web-native Rust apps (what will YOU build?)
[video] Rapid Prototyping in Rust: Write fast like Python; Run fast like C
[video] Let our rusty crab explore the depths of the C by Yvan Sraka
[video] Case Study: Rust in axle OS by Philip Tennen
[video] Aya: Extending the Linux Kernel with eBPF and Rust by Michal Rostecki
[video] Building a Lightweight IR and Backend for YJIT / Maxime Chevalier-Boisvert
[video] RustcContributor::explore: @compiler-errors session - RPITIT deep dive
Step-by-step guide to building a web-crawler
SQLx in 12 minutes - Rust + Actix Web + PostgreSQL
Bevy Basics Scenes(re-upload)
Crate of the Week
This week's crate is humantime, a parser and formatter for std::time::{Duration, SystemTime}.
Thanks to Aleksey Kladov for the suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but didn't know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
zerocopy - Optimize caching in CI
boa - hacktoberfest issues
boa - bugs that cause boa to panic
Ockam - Show "help" output when no args passed on subscription show clap command
Ockam - Add argument to node create clap command to terminate on EOF on STDIN
Ockam - Extract duplicated code into a shared helper function
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
398 pull requests were merged in the last week
linker: fix weak lang item linking with combination windows-gnu + LLD + LTO
recover when unclosed char literal is parsed as a lifetime in some positions
allow #[unstable] impls for fn() with unstable abi
allow Vec::leak when using no_global_oom_handling
allow semicolon after closure within parentheses in macros
change unknown_lint applicability to MaybeIncorrect
require Drop impls to have the same constness on its bounds as the bounds on the struct have
require lifetime bounds for opaque types in order to allow hidden types to capture said lifetimes
add default trait implementations for "c-unwind" ABI function pointers
filtering spans when emitting json
suggest let for assignment, and some code refactor
do not suggest trivially false const predicates
standardize "use parentheses to call" suggestions between typeck and trait selection
escape string literals when fixing overlong char literal
handle return-position impl Trait in traits properly in register_hidden_type
improve "~const is not allowed here" message
add diagnostic for calling a function with the same name with unresolved Macro
chalk: consider ADT's generic parameters
miri: fix ICE when trying to GC a Stack with an unknown bottom
miri: add scalar-abi-only field retagging option
erase regions before checking for Default in uninitialized binding error
introduce deduced parameter attributes, and use them for deducing readonly on indirect immutable freeze by-value function parameters
let expressions on RHS shouldn't be terminating scopes
make diagnostic for unsatisfied Termination bounds more precise
make order_dependent_trait_objects show up in future-breakage reports
reduce false positives in msys2 detection
enable LTO for rustc_driver.so
remove byte swap of valtree hash on big endian
remove more attributes from metadata
use Set instead of Vec in transitive_relation
sort tests at compile time, not at startup
use already checked RHS ty for LHS deref suggestions
stabilize proc_macro::Span::source_text
stabilize duration_checked_float
stabilize asm_sym
make transpose const and inline
mark std::os::wasi::io::AsFd etc. as stable
eliminate 280-byte memset from ReadDir iterator
optimize slice_iter.copied().next_chunk()
implement String::leak
adjust argument type for mutable with_metadata_of
hashbrown: add support for 16-bit targets
futures: do not store items field in ReadyChunks
cargo: fix publishing with a dependency on a sparse registry
cargo: improve the error message if publish is false or empty list
cargo: publish: check remote git registry more than once post-publish
rustdoc: eliminate uses of EarlyDocLinkResolver::all_traits
rustdoc: do not filter out cross-crate Self: Sized bounds
crates.io: introduce daily limit of published versions per crate
docs.rs: perf: change the link in the topbar to avoid a redirect
bindgen: avoid suppressing panic messages
bindgen: use panic hooks instead of using catch_unwind
clippy: add missing_trait_methods lint
clippy: add lint to tell about let else pattern
clippy: enable test no_std_main_recursion
clippy: fix allow_attributes_without_reason applying to external crate macros
clippy: fix ICE due to out-of-bounds array access
clippy: improvement for equatable_if_let
clippy: collapsible_match specify field name when destructuring structs
clippy: unwrap_used, expect_used do not lint in test cfg
clippy: ref_option_ref do not lint when inner reference is mutable
clippy: add from_raw_with_void_ptr lint
clippy: fix box-default ignoring trait objects' types
clippy: support map_or for or_fun_call lint
rust-analyzer: support const generics for builtin derive macro
rust-analyzer: workaround the python vscode extension's polyfill
rust-analyzer: add multiple getters mode in generate_getter
rust-analyzer: don't catch the server activation error
rust-analyzer: don't respond with an error when requesting a shutdown while starting
rust-analyzer: fix DidSaveDocument requests blocking the server on startup
rust-analyzer: fix standard flycheck command not being executed in the workspace it is being invoked for
rust-analyzer: handle multiple projects sharing dependency correctly in once strategy
Rust Compiler Performance Triage
An amazing week. We saw more wins than losses; I want to call out specifically the wins from removing attributes from metadata (up to 8.2% faster builds for 18 benchmarks) and from enabling LTO for rustc_driver.so (up to 9.6% faster builds for an epic 230 benchmarks, with zero regressions).
Triage done by @pnkfelix. Revision range: e0f8e60d..629a414d
2 Regressions, 6 Improvements, 2 Mixed; 2 of them in rollups 53 artifact comparisons made in total
See full report for details.
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Make PROC_MACRO_DERIVE_RESOLUTION_FALLBACK a hard error
[disposition: merge] Elaborate supertrait obligations when deducing closure signatures
[disposition: merge] Tracking Issue for Integer::{ilog,ilog2,ilog10}
[disposition: close] Propagate deref coercion into block
[disposition: merge] Derive Eq and Hash for ControlFlow
New and Updated RFCs
[new] Warning on unintended implicit drops
[new] Niches
[new] Deprecate PhantomData dropck
Upcoming Events
Rusty Events between 2022-10-26 - 2022-11-23 🦀
Virtual
2022-10-26 | Virtual (Redmond, WA, US / New York, NY, US / Toronto, CA / Stockholm, SE / London, UK) | Microsoft Reactor Redmond
Your First Rust Project: Rust Basics | New York Mirror | Toronto Mirror | Stockholm Mirror | London Mirror
2022-10-27 | Virtual (Charlottesville, VA, US) | Charlottesville Rust Meetup
Using Applicative Functors to parse command line options
2022-10-27 | Virtual (Karlsruhe, DE) | The Karlsruhe Functional Programmers Meetup Group
Stammtisch (gemeinsam mit der C++ UG KA) (various topics, from C++ to Rust...)
2022-10-27 | Virtual (Linz, AT) | Rust Linz
Rust Meetup Linz - 26th Edition
2022-10-29 | Virtual (Ludwigslust, DE) | Ludwigslust Rust Meetup
Von Nullen und Einsen | Rust Meetup Ludwigslust #1
2022-11-01 | Virtual (Beijing, CN) | WebAssembly and Rust Meetup (Rustlang)
Monthly WasmEdge Community Meeting, a CNCF sandbox WebAssembly runtime
2022-11-01 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2022-11-02 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
Rust and C++ Cardiff Virtual Meet
2022-11-02 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2022-11-02 | Virtual (Redmond, WA, US / San Francisco, SF, US / New York, NY, US / Toronto, CA / London, UK) | Microsoft Reactor Redmond
Getting Started with Rust: From Java Dev to Rust Developer | San Francisco Mirror | New York Mirror | Toronto Mirror | London Mirror
2022-11-02 | Virtual (Stuttgart, DE) | Rust Community Stuttgart
Rust-Meetup
2022-11-08 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn
2022-11-08 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2022-11-08 | Virtual (Rostock, DE) | Altow Academy
Rust Meetup Rostock
2022-11-08 | Virtual (Stockholm, SE) | Func Prog Sweden
Tenth Func Prog Sweden MeetUp 2022 – Online (with "Ready for Rust" by Erik Dörnenburg)
2022-11-09 | Virtual (Malaysia, MY) | Rust Malaysia
Rust Meetup November 2022 - a couple of lightning talks
2022-11-10 | Virtual (Budapest, HU) | HWSW free!
RUST! RUST! RUST! meetup (online formában!)
2022-11-12 | Virtual | Rust GameDev
Rust GameDev Monthly Meetup
2022-11-15 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
2022-11-15 | Virtual (Nairobi, KE / New York, NY, US)| Data Umbrella Africa
Online: Introduction to Rust Programming | New York Mirror
2022-11-16 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2022-11-17 | Virtual (Amsterdam, NL) | ITGilde Tech-Talks
Introduction “Rust” an ITGilde Tech Talk delivered by Pascal van Dam
2022-11-21 | Virtual (Paris, FR) | Meetup Paris - École Supérieure de Génie Informatique (ESGI)
Découverte de WebAssembly
Asia
2022-11-08 | Bangkok, TH | Tech@Agoda
Rustacean Bangkok 5.0.0
Europe
2022-10-26 | London, UK | Rust London User Group
LDN Talks October 2022: Host by Amazon Prime Video
2022-10-26 | Bristol, UK | Rust and C++ Cardiff/Rust Bristol
Programming Veloren & Rust for a living
2022-10-27 | København, DK | Copenhagen Rust Group
Hack Night #30
2022-11-23 | Bratislava, SK | Bratislava Rust Meetup Group
Initial Meet and Greet Rust meetup
North America
2022-10-27 | Lehi, UT, US | Utah Rust
Bevy Crash Course with Nathan and Food!
2022-11-10 | Columbus, OH, US | Columbus Rust Society
Monthly Meeting
Oceania
2022-11-09 | Sydney, NSW, AU | Rust Sydney
RustAU Sydney - Last physical for 2022 !
2022-11-22 | Canberra, ACT, AU | Canberra Rust User Group
November Meetup
South America
2022-11-05 | São Paulo, SP, BR | Rust São Paulo Meetup
Rust-SP meetup Outubro 2022
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
Also, I don't know how much of this is because Rust is special or because BurntSushi is a national treasure and his CSV library is impeccably constructed and documented.
– Gabe Durazo on github
Thanks to scottmcm for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
0 notes
Text
USPS Address Standardization API
USPS Address Standardization API is one of the three address validation suites offered by the United States Postal Service. It automates the process of verifying or validating addresses saving businesses hours and oodles of money. These APIs are highly integrable and can be integrated with a website, database, and CRM among others. They are designed to ensure that address information is standardized according to the guidelines of the USPS, thus maintaining the highest accuracy for deliverability.

The address verification process first involves parsing and standardizing the address. Addresses are broken down into components like the house number, street type, and street name. Then the data is compared against the authoritative database (the USPS in the case of domestic addresses) to check for consistency and error. Errors in casing, abbreviation, and spelling are corrected to match the official formats.
In the case of USPS addresses, a delivery point validation is performed as well. This is done by analyzing the standardized address to find out whether or not it is a unique deliverable address with a secondary designator, such as apartment or suite. Lob’s Address Verification API also includes an Enhanced DPV analysis that provides a binary outcome, such as valid or invalid.
Other address validation solutions use a combination of scripts and APIs to do the work for you. This includes tools like geocodio, which allows you to input your addresses in an Excel spreadsheet and have it automatically parse and standardize them for you. Another option is the free Excel plugin from CDX Technologies, which lets you paste in address lists and automatically validates and corrects them.
youtube
SITES WE SUPPORT
Mail Api Response – Blogger
0 notes
Text
Why Your Website Needs to Be Integrated With the FedEx Address Validation API

If you use a FedEx shipping solution such as WooCommerce FedEx Shipping Plugin or Shopify FedEx App, your website may need to be integrated with the FedEx Address Validation API. This is necessary for proper address validation, and ensuring that your customers can get accurate rates on their orders.
Once the address is standardized and parsed, it’s compared against a database that’s the authoritative standard for that country’s postal system, such as USPS for addresses in the United States. This is when the system determines whether it’s a valid or invalid address and if not, why not.
A good address verification solution will also be able to determine the type of an address, whether it’s commercial or residential. This is important for determining carrier rates because some carriers have different pricing for business or residential deliveries. The system can also be set to differentiate between PO boxes and actual houses/businesses.
One of the most common reasons an address is deemed invalid is human error. This can be anything from a severe misspelling to flipping or scrambling numbers in the street or zip code. Even if the person who entered the information is a trained postal worker, mistakes can happen.
To reduce the likelihood of these errors, you should implement a process to refresh and synchronize address databases periodically to ensure accuracy. It’s also a good idea to train employees on how to properly enter and validate addresses. This can save money in the long run by reducing the number of returned items and preventing delivery delays due to incorrect address data.
youtube
"
SITES WE SUPPORT
Address verification software – Weebly
SOCIAL LINKS
Facebook Twitter LinkedIn Instagram Pinterest
"
1 note
·
View note
Text
How to fix wp rocket plugin installation error in CPanel
How to fix wp rocket plugin installation error in CPanel
How to fix wp rocket plugin installation error in CPanel ▶️ DON’T CLICK THIS LINK: https://bit.ly/3bEWPsx ▶️ Other videos: • How to Get More Followers on TikTok: https://youtu.be/OdaFkbRG-xQ • How to Add Website on CLOUDFLARE: https://youtu.be/3cF_8dFgpbY • How To Check MTN Phone Number in 3 Simple Ways Using USSD Code: https://youtu.be/4LpJBK4q9Ng • How to limit crawl rate in Google Search…

View On WordPress
#fix php parse error syntax error unexpected#fix wp rocket install error#how to fix wp rocket plugin installation error in cpanel#ktm#parse error#parse error syntax error unexpected#plugin parse error#plugin parse errors#syntax error#update failed plugin wordpress#wordpress plugin#wordpress tutorial#wp#wp plugin install error#wp rocket#wp rocket parse errors#wp rocket plugin parse error#wp rocket settings#wp rocket wordpress plugin#wprocket plugin install error
0 notes
Text
Complete Flutter and Dart Roadmap 2020
Mohammad Ali Shuvo
Oct 30, 2020·4 min read
DART ROADMAP
Basics
Arrays, Maps
Classes
Play On Dart Compiler
String Interpolation
VARIABLES
var
dynamic
int
String
double
bool
runes
symbols
FINAL AND CONST
differences
const value and const variable
NUMBERS
hex
exponent
parse methods
num methods
math library
STRINGS
methods
interpolation
multi-line string
raw string
LISTS
List (Fixed and Growable)
methods
MAPS
Map (Fixed and Growable)
methods
SETS
Set ((Fixed and Growable)
methods
FUNCTIONS
Function as a variabl
optional and required parameters
fat arrow
named parameters
@required keyword
positional parameters
default parameter values
Function as first-class objects
Anonymous functions
lexical scopes
Lexical closures
OPERATORS
unary postfix expr++ expr — () [] . ?.
unary prefix -expr !expr ~expr ++expr — expr await expr
multiplicative * / % ~/
additive + -
shift << >> >>>
bitwise AND &
bitwise XOR ^
bitwise OR |
relational and type test >= > <= < as is is!
equality == !=
logical AND &&
logical OR ||
if null ??
conditional expr1 ? expr2 : expr3
cascade ..
assignment = *= /= += -= &= ^= etc.
CONTROL FLOW STATEMENTS
if and else
for loops
while and do-while
break and continue
switch and case
assert
EXCEPTIONS (ALL ARE UNCHECKED)
Throw
Catch
on
rethrow
finally
CLASSES
Class members
Constructors
Getting object type
instance variables
getters and setters
Named constructors
Initializer lists
Constant constructors
Redirecting constructors
Factory constructors
instance methods
abstract methods
abstract classes
Inheritance
Overriding
Overriding operators
noSuchMethod()
Extension methods
Enums
Mixins (on keyword in mixins)
Static keyword, static variables and methods
GENERICS
Restricting the parameterized type
Using generic methods
LIBRARIES AND VISIBILITY
import
as
show
hide
deferred
ASYNCHRONY SUPPORT
Futures
await
async
Streams
Stream methods
OTHER TOPICS
Generators
Callable classes
Isolates
Typedefs
Metadata
Custom annotation
Comments, Single-line comments, Multi-line comments, Documentation comments
OTHER KEYWORDS FUNCTIONS
covariant
export
external
part
sync
yield
FLUTTER ROADMAP
Flutter Installation (First App)
Flutter Installation
Basic Structure
Android Directory Structure
iOS Directory Structure
BASICS
MaterialApp
Scaffold
AppBar
Container
Icon
Image
PlaceHolder
RaisedButton
Text
RichText
STATELESS AND STATEFULWIDGETS
Differences
When To Use?
How To Use?
Add Some Functionality
INPUT
Form
Form Field
Text Field
TextEditing Controller
Focus Node
LAYOUTS
Align
Aspect Ratio
Baseline
Center
Constrained Box
Container
Expanded
Fitted Box
FractionallySizedBox
Intrinsic Height
Intrinsic Width
Limited Box
Overflow Box
Padding
Sized Box
SizedOverflowBox
Transform
Column
Flow
Grid View
Indexed Stack
Layout Builder
List Body
List View
Row
Stack
Table
Wrap
Safe Area
MATERIAL COMPONENTS
App bar
Bottom Navigation Bar
Drawer
Material App
Scaffold
SliverAppBar
TabBar
TabBarView
WidgetsApp
NAVIGATOR
pop
Routes
Bottom Navigation
Drawer
Create Multipage App
popUntil
canPop
push
pushNamed
popAndPushNamed
replace
pushAndRemoveUntil
NavigatorObserver
MaterialRouteBuilder
BUTTONS
ButtonBar
DropdownButton
FlatButton
FloatingActionButton
IconButton
OutlineButton
PopupMenuButton
RaisedButton
INPUT AND SELECTIONS
Checkbox
Date & Time Pickers
Radio
Slider
Switch
DIALOGS, ALERTS, AND PANELS
AlertDialog
BottomSheet
ExpansionPanel
SimpleDialog
SnackBar
INFORMATION DISPLAYS
Card
Chip
CircularProgressIndicator
DataTable
LinearProgressIndicator
Tooltip
LAYOUT
Divider
ListTile
Stepper
SCROLLING
CustomScrollView
NestedScrollView
NotificationListener
PageView
RefreshIndicator
ScrollConfiguration
Scrollable
Scrollbar
SingleChildScrollView
Theory …
Flutter -Inside View
Dart
Skia Engine
Performance
Comparison
App Built In Flutter
OTHER USEFUL WIDGETS
MediaQuery
LayoutBuilder
OrientationBuilder
FutureBuilder
StreamBuilder
DraggableScrollableSheet
Learn How to Use Third Party Plugins
CUPERTINO (IOS-STYLE) WIDGETS
CupertinoActionSheet
CupertinoActivityIndicator
CupertinoAlertDialog
CupertinoButton
CupertinoContextMenu
CupertinoDatePicker
CupertinoDialog
CupertinoDialogAction
CupertinoNavigationBar
CupertinoPageScaffold
CupertinoPicker
CupertinoPageTransition
CupertinoScrollbar
CupertinoSegmentedControl
CupertinoSlider
CupertinoSlidingSegmentedControl
CupertinoSwitch
CupertinoTabBar
CupertinoTabScaffold
CupertinoTabView
CupertinoTextField
CupertinoTimerPicker
ANIMATIONS
Ticker
Animation
AnimationController
Tween animation
Physics-based animation
AnimatedWidget
AnimatedBuilder
AnimatedContainer
AnimatedOpacity
AnimatedSize
FadeTransition
Hero
RotationTransition
ScaleTransition
SizeTransition
SlideTransition
NETWORKING
http, dio libraries
json parsing
Local Persistent Storage
SQFLITE
Shared Preferences
Hive
JSON
JSON- PARSING
INTERNATIONALI ZING FLUTTER APPS
Locale
AppLocalization
json files
STATE MANAGEMENT
setState
InheritedWidget
ScopedModel
Provider
Redux
BLOC
OTHER IMPORTANT TOPICS
Widget Tree, Element Tree and Render Tree
App Lifecycle
Dynamic Theming
Flare
Overlay widget
Visibility Widget
Spacer Widget
Universal error
Search Layout
CustomPainter
WidgetsBindingObserver
RouteObserver
SystemChrome
Internet connectivity
Http Interceptor
Google Map
Firebase Auth
Cloud FireStore DB
Real time DB
File/Image Upload
Firebase database
Firestore
Semantic versioning
Finding size and position of widget using RenderObject
Building release APK
Publishing APK on Play Store
RxDart
USEFUL TOOLS
Dev Tools
Observatory
Git and GitHub
Basics
Add ,Commit
Push
Pull
Github,Gitlab And Bitbucket
Learn How to Become UI Pro
Recreate Apps
Animations
Dribble -App Ui
Make Custom Widgets
Native Components
Native Share
Permissions
Local Storage
Bluetooth
WIFI
IR Sensor
API -REST/GRAPH
Consume API
Basics of Web Dev
Server
TESTING AND DEBUGGING
Debugging
Unit Testing
UI (Widget) Testing
Integration Testing
WRITING CUSTOM PLATFORM-SPECIFIC CODE
Platform Channel
Conclusion: There are some courses out there but I believe self-learning is the best. However, you can take help whenever you feel like it. Continue Your Journey By making Apps and also You can clone the existing apps for learning the concept more clearly like Ecommerce , Instagram , Expense Manager , Messenger ,bla bla …….
Most important thing to remember that don’t depend on others too much , when you face any problem just google it and a large flutter community is always with you.
Best of luck for your Flutter journey
Get Ready and Go………..
1 note
·
View note
Text
Sqlite For Mac Os X

Sqlite For Mac Os X El Capitan
Sqlite Viewer Mac
Sqlite Mac Os X Install
If you are looking for an SQLite Editor in the public domain under Creative Commons license or GPL (General Public License) i.e. for free commercial or non-commercial use. Then here is a shortlist of the SQLite Editor that is available on the web for free download.
SQLite is famous for its great feature zero-configuration, which means no complex setup or administration is needed. This chapter will take you through the process of setting up SQLite on Windows, Linux and Mac OS X. Install SQLite on Windows. Step 1 − Go to SQLite download page, and download precompiled binaries from Windows section. Core Data is an object graph and persistence framework provided by Apple in the macOS and iOS operating systems.It was introduced in Mac OS X 10.4 Tiger and iOS with iPhone SDK 3.0. It allows data organized by the relational entity–attribute model to be serialized into XML, binary, or SQLite stores. The data can be manipulated using higher level objects representing entities. Requirements: Free, ideally open source Browse schema, data. Run queries Bonus if updated in near real time when the file is. SQLite viewer for Mac OS X. Ask Question Asked 5 years, 10 months ago. Active 4 years, 3 months ago. Viewed 504 times 3. I need to inspect an SQLite file on Mac. Since I develop on Windows, Linux and OS X, it helps to have the same tools available on each. I also tried SQLite Admin (Windows, so irrelevant to the question anyway) for a while, but it seems unmaintained these days, and has the most annoying hotkeys of any application I've ever used - Ctrl-S clears the current query, with no hope of undo.
These software work on macOS, Windows, Linux and most of the Unix Operating systems.
SQLite is the server. The SQLite library reads and writes directly to and from the database files on disk. SQLite is used by Mac OS X software such as NetNewsWire and SpamSieve. When you download SQLite and build it on a stock Mac OS X system, the sqlite tool has a.
1. SQLiteStudio
Link : http://sqlitestudio.pl/
SQLiteStudio Database manager has the following features :
A small single executable Binary file, so there is need to install or uninstall.
Open source and free - Released under GPLv2 licence.
Good UI with SQLite3 and SQLite2 features.
Supports Windows 9x/2k/XP/2003/Vista/7, Linux, MacOS X, Solaris, FreeBSD and other Unix Systems.
Language support : English, Polish, Spanish, German, Russian, Japanese, Italian, Dutch, Chinese,
Exporting Options : SQL statements, CSV, HTML, XML, PDF, JSON, dBase
Importing Options : CSV, dBase, custom text files, regular expressions
UTF-8 support

2. Sqlite Expert
Link : http://www.sqliteexpert.com/download.html


SQLite Expert though not under public domain, but its free for commercial use and is available in two flavours.
a. Personal Edition
Sqlite For Mac Os X El Capitan
It is free for personal and commercial use but, covers only basic SQLite features.
But its a freeware and does not have an expiration date.

b. Professional Edition
It is for $59 (onetime fee, with free lifetime updates )
It covers In-depth SQLite features.
But its a freeware and does not have an expiration date.
Features :
Visual SQL Query Builder : with auto formatting, sql parsing, analysis and syntax highlighting features.
Powerful restructure capabilities : Restructure any complex table without losing data.
Import and Export data : CSV files, SQL script or SQLite. Export data to Excel via clipboard.
Data editing : using powerful in-place editors
Image editor : JPEG, PNG, BMP, GIF and ICO image formats.
Full Unicode Support.
Support for encrypted databases.
Lua and Pascal scripting support.
3. Database Browser for SQLite
Link : http://sqlitebrowser.org/
Database Browser for SQLite is a high quality, visual, open source tool to create, design, and edit database files compatible with SQLite.
Database Browser for SQLite is bi-licensed under the Mozilla Public License Version 2, as well as the GNU General Public License Version 3 or later.
You can modify or redistribute it under the conditions of these licenses.
Features :
You can Create, define, modify and delete tables
You can Create, define and delete indexes
You can Browse, edit, add and delete records
You can Search records
You can Import and export records as
You can Import and export tables from/to text, CSV, SQL dump files
You can Issue SQL queries and inspect the results
You can See Log of all SQL commands issued by the application
4. SQLite Manager for Firefox Browser
Link : https://addons.mozilla.org/en-US/firefox/addon/sqlite-manager/
This is an addon plugin for Firefox Browser,
Features :
Manage any SQLite database on your computer.
An intuitive hierarchical tree showing database objects.
Helpful dialogs to manage tables, indexes, views and triggers.
You can browse and search the tables, as well as add, edit, delete and duplicate the records.
Facility to execute any sql query.
The views can be searched too.
A dropdown menu helps with the SQL syntax thus making writing SQL easier.
Easy access to common operations through menu, toolbars, buttons and context-menu.
Export tables/views/database in csv/xml/sql format. Import from csv/xml/sql (both UTF-8 and UTF-16).
Possible to execute multiple sql statements in Execute tab.
You can save the queries.
Support for ADS on Windows
Sqlite Viewer Mac
More Posts related to Mac-OS-X,
More Posts:
Sqlite Mac Os X Install
Facebook Thanks for stopping by! We hope to see you again soon. - Facebook
Android EditText Cursor Colour appears to be white - Android
Disable EditText Cursor Android - Android
Connection Failed: 1130 PHP MySQL Error - MySQL
SharePoint Managed Metadata Hidden Taxonomy List - TaxonomyHiddenList - SharePoint
Execute .bin and .run file Ubuntu Linux - Linux
Possible outages message Google Webmaster tool - Google
Android : Remove ListView Separator/divider programmatically or using xml property - Android
Unable to edit file in Notepad++ - NotepadPlusPlus
SharePoint PowerShell Merge-SPLogFile filter by time using StartTime EndTime - SharePoint
SQLite Error: unknown command or invalid arguments: open. Enter .help for help - Android
JBoss stuck loading JBAS015899: AS 7.1.1.Final Brontes starting - Java
Android Wifi WPA2/WPA Connects and Disconnects issue - Android
Android Toolbar example with appcompat_v7 21 - Android
ERROR x86 emulation currently requires hardware acceleration. Intel HAXM is not installed on this machine - Android
1 note
·
View note
Text
Mint: late-stage adversarial interoperability demonstrates what we had (and what we lost)
In 2006, Aaron Patzer founded Mint. Patzer had grown up in the city of Evansville, Indiana—a place he described as "small, without much economic opportunity"—but had created a successful business building websites. He kept up the business through college and grad school and invested his profits in stocks and other assets, leading to a minor obsession with personal finance that saw him devoting hours every Saturday morning to manually tracking every penny he'd spent that week, transcribing his receipts into Microsoft Money and Quicken.
Patzer was frustrated with the amount of manual work it took to track his finances with these tools, which at the time weren't smart enough to automatically categorize "Chevron" under fuel or "Safeway" under groceries. So he conceived on an ingenious hack: he wrote a program that would automatically look up every business name he entered into the online version of the Yellow Pages—constraining the search using the area code in the business's phone number so it would only consider local merchants—and use the Yellow Pages' own categories to populate the "category" field in his financial tracking tools.
It occurred to Patzer that he could do even better, which is where Mint came in. Patzer's idea was to create a service that would take all your logins and passwords for all your bank, credit union, credit card, and brokerage accounts, and use these logins and passwords to automatically scrape your financial records, and categorize them to help you manage your personal finances. Mint would also analyze your spending in order to recommend credit cards whose benefits were best tailored to your usage, saving you money and earning the company commissions.
By international standards, the USA has a lot of banks: around 12,000 when Mint was getting started (in the US, each state gets to charter its own banks, leading to an incredible, diverse proliferation of financial institutions). That meant that for Mint to work, it would have to configure its scrapers to work with thousands of different websites, each of which was subject to change without notice.
If the banks had been willing to offer an API, Mint's job would have been simpler. But despite a standard format for financial data interchange called OFX (Open Financial Exchange), few financial institutions were offering any way for their customers to extract their own financial data. The banks believed that locking in their users' data could work to their benefit, as the value of having all your financial info in one place meant that once a bank locked in a customer for savings and checking, it could sell them credit cards and brokerage services. This was exactly the theory that powered Mint, with the difference that Mint wanted to bring your data together from any financial institution, so you could shop around for the best deals on cards, banking, and brokerage, and still merge and manage all your data.
At first, Mint contracted with Yodlee, a company that specialized in scraping websites of all kinds, combining multiple webmail accounts with data scraped from news sites and other services in a single unified inbox. When Mint outgrew Yodlee's services, it founded a rival called Untangly, locking a separate team in a separate facility that never communicated with Mint directly, in order to head off any claims that Untangly had misappropriated Yodlee's proprietary information and techniques—just as Phoenix computing had created a separate team to re-implement the IBM PC ROMs, creating an industry of "PC clones."
Untangly created a browser plugin that Mint's most dedicated users would use when they logged into their banks. The plugin would prompt them to identify elements of each page in the bank's websites so that the scraper for that site could figure out how to parse the bank's site and extract other users' data on their behalf.
To head off the banks' countermeasures, Untangly maintained a bank of cable-modems and servers running "headless" versions of Internet Explorer (a headless browser is one that runs only in computer memory, without drawing the actual browser window onscreen) and they throttled the rate at which the scripted interactions on these browsers ran, in order to make it harder for the banks to determine which of its users were Mint scrapers acting on behalf of its customers and which ones were the flesh-and-blood customers running their own browsers on their own behalf.
As the above implies, not every bank was happy that Mint was allowing its customers to liberate their data, not least because the banks' winner-take-all plan was for their walled gardens to serve as reasons for customers to use their banks for everything, in order to get the convenience of having all their financial data in one place.
Some banks sent Mint legal threats, demanding that they cease-and-desist from scraping customer data. When this happened, Mint would roll out its "nuclear option"—an error message displayed to every bank customer affected by these demands informing them that their bank was the reason they could no longer access their own financial data. These error messages would also include contact details for the relevant decision-makers and customer-service reps at the banks. Even the most belligerent bank's resolve weakened in the face of calls from furious customers who wanted to use Mint to manage their own data.
In 2009, Mint became a division of Intuit, which already had a competing product with a much larger team. With the merged teams, they were able to tackle the difficult task of writing custom scrapers for the thousands of small banks they'd been forced to sideline for want of resources.
Adversarial interoperability is the technical term for a tool or service that works with ("interoperates" with) an existing tool or service—without permission from the existing tool's maker (that's the "adversarial" part).
Mint's story is a powerful example of adversarial interoperability: rather than waiting for the banks to adopt standards for data-interchange—a potentially long wait, given the banks' commitment to forcing their customers into treating them as one-stop-shops for credit cards, savings, checking, and brokerage accounts—Mint simply created the tools to take its users' data out of the bank's vaults and put it vaults of the users' choosing.
Adversarial interoperability was once commonplace. It's a powerful way for new upstarts to unseat the dominant companies in a market—rather than trying to convince customers to give up an existing service they rely on, an adversarial interoperator can make a tool that lets users continue to lean on the existing services, even as they chart a path to independence from those services.
But stories like Mint are rare today, thanks to a sustained, successful campaign by the companies that owe their own existence to adversarial interoperability to shut it down, lest someone do unto them as they had done unto the others.
Thanks to decades of lobbying and lawsuits, we've seen a steady expansion of copyright rules, software patents (though these are thankfully in retreat today), enforceable terms-of-service and theories about "interference with contract" and "tortious interference."
These have grown to such an imposing degree that big companies don't necessarily need to send out legal threats or launch lawsuits anymore—the graveyard of new companies killed by these threats and suits is scary enough that neither investors nor founders have much appetite for risking it.
For Mint to have launched when it did, and done as well as it did, tells us that adversarial interoperability may be down, but it's not out. With the right legal assurances, there are plenty of entrepreneurs and investors who'd happily provide users with the high-tech ladders they need to scale the walled gardens that Big Tech has imprisoned them within.
The Mint story also addresses an important open question about adversarial interoperability: if we give technologists the right to make these tools, will they work? After all, today's tech giants have entire office-parks full of talented programmers. Can a new market entrant hope to best them in the battle of wits that plays out when they try to plug some new systems into Big Tech's existing ones?
The Mint experience points out that attackers always have an advantage over defenders. For the banks to keep Mint out, they'd have to have perfect scraper-detection systems. For Mint to scrape the banks' sites, they only need to find one flaw in the banks' countermeasures.
Mint also shows how an incumbent company's own size works against it when it comes to shutting out competitors. Recall that when a bank decided to send its lawyers after Mint, Mint was able to retaliate by recruiting the bank's own customers to blast it for that decision. The more users Mint had, the more complaints it would generate—and the bigger a bank was, the more customers it had to become Mint users, and defenders of Mint's right to scrape the bank's site.
It's a neat lesson about the difference between keeping out malicious hackers versus keeping out competitors. If a "bad guy" was attacking the bank's site, it could pull out all the stops to shut the activity down: lawsuits, new procedures for users to follow, even name-and-shame campaigns against the bad actor.
But when a business attacks a rival that is doing its own customers' bidding, its ability to do so has to be weighed against the ill will it will engender with those customers, and the negative publicity this kind of activity will generate. Consider that Big Tech platforms claim billions of users—that's a huge pool of potential customers for adversarial interoperators who promise to protect those users from Big Tech's poor choices and exploitative conduct!
This is also an example of how "adversarial interoperability" can peacefully co-exist with privacy protection: it's not hard to see how a court could distinguish between a company that gets your data from a company's walled garden at your request so that you can use it, and a company that gets your data without your consent and uses it to attack you.
Mint's pro-competitive pressure made banks better, and gave users more control. But of course, today Mint is a division of Intuit, a company mired in scandal over its anticompetitive conduct and regulatory capture, which have allowed it to subvert the Free File program that should give millions of Americans access to free tax-preparation services.
Imagine if an adversarial interoperator were to enter the market today with a tool that auto-piloted its users through the big tax-prep companies' sites to get them to Free File tools that would actually work for them (as opposed to tricking them into expensive upgrades, often by letting them get all the way to the end of the process before revealing that something about the user's tax situation makes them ineligible for that specific Free File product).
Such a tool would be instantly smothered with legal threats, from "tortious interference" to hacking charges under the Computer Fraud and Abuse Act. And yet, these companies owe their size and their profits to exactly this kind of conduct.
Creating legal protections for adversarial interoperators won't solve all our problems of market concentration, regulatory capture, and privacy violations—but giving users the right to control how they interact with the big services would certainly open a space where technologists, co-ops, entrepreneurs and investors could help erode the big companies' dominance, while giving the public a better experience and a better deal.
https://www.eff.org/deeplinks/2019/12/mint-late-stage-adversarial-interoperability-demonstrates-what-we-had-and-what-we
16 notes
·
View notes
Text
Address Autocomplete API Free
Using an address autocomplete api free on your form prevents you from ingesting inaccurate data like typos and nonexistent addresses. It also reduces the number of keystrokes at the point of entry and improves user experience, address reliability & conversion rates.

Whether you’re shipping packages or sending marketing mailers to customers, accurate and complete addresses are essential to your business operations. An efficient address autocomplete feature on your website helps you avoid problems like incorrect shipping addresses resulting in delayed or returned deliveries, costly extra charges, warnings in your CRM/ ERP system, etc.
A reliable address verification service sustains automated standardizations, parsing, customer/ user identity validation, and enables you to remove invalid addresses from your database. The address lookup api free that you use on your website can also verify suite and apartment information, support different languages and character sets, and transliterate address texts into scripts as needed for international addresses.
Most global address autocomplete services, such as Google Places, rely on untrained volunteers to report street, business and residential addresses. Because of this, the accuracy varies significantly. In addition, many of them fail to provide accurate data on suites and apartments in the USA, which means that they are missing a lot of important addresses.
youtube
On the other hand, our international address autocomplete api free can predict global addresses in real-time and correct them as they are being entered by users. It has data for over 245 countries and also provides transliteration to support different languages and characters. It works with the standardized format used by most countries and helps reduce typing errors and typos. The plugin integrates with Gravity Forms and can be enabled directly from the form settings with one click.
SITES WE SUPPORT
Address Autocomplete Api – Wix
0 notes
Text
WordPress code editor enables editing theme and plugin files directly from wp-admin. Precautionary it is recommended to turn it off, as it is a potential security hazard. Version after 4.9 can catch fatal errors and does not parse the code till they are resolved. Furthermore, it stops the hacker with administrator access by changing themes or plugins and inserting malicious code.

How to Disable file editing in WordPress admin?
Log into the control panel.
Open File Manager under Files & Security.
Locate the file wp-config.
Click Edit in the menu bar at the top of your screen.
Search wp-config for ‘DISALLOW_FILE_EDIT’, and DISALLOW_FILE_MODS’ and set it to “true”
define('DISALLOW_FILE_EDIT', true); define( 'DISALLOW_FILE_MODS', true );
Recently, a security alert revealed that WordPress websites on Linux were targeted by a previously unknown strain of Linux malware that exploits flaws in over two dozen plugins and themes to compromise vulnerable systems. The targeted websites were injected with malicious JavaScript retrieved from a remote server. As a result, when visitors click on any area of an infected page, they are redirected to another arbitrary website of the attacker’s choice.
The disclosure comes weeks after Fortinet FortiGuard Labs detailed another botnet called GoTrim that’s designed to brute-force self-hosted websites using the WordPress content management system (CMS) to seize control of targeted systems. In June 2022, the GoDaddy-owned website security company shared information about a traffic direction system (TDS) known as Parrot that has been observed targeting WordPress sites with rogue JavaScript that drops additional malware onto hacked systems. Last month, Sucuri noted that more than 15,000 WordPress sites had been breached as part of a malicious campaign to redirect visitors to bogus Q&A portals. The number of active infections currently stands at 9,314. January 03, 2023, BleepingComputer reports thirty security vulnerabilities in numerous outdated WordPress plugins and themes are being leveraged by a novel Linux malware to facilitate malicious JavaScript injections. Dr. Web reported that malware compromised both 32- and 64-bit Linux systems, and uses a set of successively running hardcoded exploits to compromise WordPress sites.
You can look to the Ananova selected top hosting providers at: https://ananova.com/best-hosting-providers
The key players listed in the list include Liquidweb, WordPress.com, A2Hosting, GreenGeeks, Namecheap, Inmotionhosting, Resellerspanel, Hostgator, Interserver, Sitevalley, Webhostingpad, Bluehost, Hostmonster, Fatcow, IPower, Weebly, Shopify, Accuwebhosting, WPEngine, Cloudways, Hostens and many more.
0 notes
Text
Disable File Editing on WordPress
Disable File Editing on WordPress
(Ananova News) January 04, 2023. WordPress code editor enables editing theme and plugin files directly from wp-admin. Precautionary it is recommended to turn it off, as it is a potential security hazard. Version after 4.9 can catch fatal errors and does not parse the code till they are resolved. Furthermore, it stops the hacker with administrator access by changing themes or plugins and…
View On WordPress
0 notes
Text
Tech For Today Series - Day 1
This is first article of my Tech series. Its collection of basic stuffs of programming paradigms, Software runtime architecture ,Development tools ,Frameworks, Libraries, plugins and JAVA.
Programming paradigms
Do you know about program ancestors? Its better to have brief idea about it. In 1st generation computers used hard wired programming. In 2nd generation they used Machine language. In 3rd generation they started to use high level languages and in 4th generation they used advancement of high level language. In time been they introduced different way of writing codes(High level language).Programming paradigms are a way to classify programming language based on their features (WIKIPEDIA). There are lots of paradigms and most well-known examples are functional programming and object oriented programming.
Main target of a computer program is to solve problem with right concept. To solve problem it required different concept for different part of the problems. Because of that its important that programming languages support many paradigms. Some computer languages support multiple programming paradigms. As example c++ support both functional programming and oop.
On this article we discuss mainly about Structured programming, Non Structured Programming and event driven programming.
Non Structured Programming
Non-structured programming is the earliest programming paradigm. Line by line theirs no additional structure. Entire program is just list of code. There’s no any control structure. After sometimes they use GOTO Statement. Non Structured programming languages use only basic data types such as numbers, strings and arrays . Early versions of BASIC, Fortran, COBOL, and MUMPS are example for languages that using non structures programming language When number of lines in the code increases its hard to debug and modify, difficult to understand and error prone.
Structured programming
When the programs grows to large scale applications number of code lines are increase. Then if non structured program concept are use it will lead to above mentioned problems. To solve it Structured program paradigm is introduced. In first place they introduced Control Structures.
Control Structures.
Sequential -Code execute one by one
Selection - Use for branching the code (use if /if else /switch statements)
Iteration - Use for repetitively executing a block of code multiple times
But they realize that control structure is good to manage logic. But when it comes to programs which have more logic it will difficult to manage the program. So they introduce block structure (functional) programming and object oriented programming. There are two types of structured programming we talk in this article. Functional (Block Structured ) programming , Object oriented programming.
Functional programming
This paradigm concern about execution of mathematical functions. It take argument and return single solution. Functional programming paradigm origins from lambda calculus. " Lambda calculus is framework developed by Alonzo Church to study computations with functions. It can be called as the smallest programming language of the world. It gives the definition of what is computable. Anything that can be computed by lambda calculus is computable. It is equivalent to Turing machine in its ability to compute. It provides a theoretical framework for describing functions and their evaluation. It forms the basis of almost all current functional programming languages. Programming Languages that support functional programming: Haskell, JavaScript, Scala, Erlang, Lisp, ML, Clojure, OCaml, Common Lisp, Racket. " (geeksforgeeks). To check how lambda expression in function programming is work can refer with this link "Lambda expression in functional programming ".
Functional code is idempotent, the output value of a function depends only on the arguments that are passed to the function, so calling a function f twice with the same value for an argument x produces the same result f(x) each time .The global state of the system does not affect the result of a function. Execution of a function does not affect the global state of the system. It is referential transparent.(No side effects)
Referential transparent - In functional programs throughout the program once define the variables do not change their value. It don't have assignment statements. If we need to store variable we create new one. Because of any variable can be replaced with its actual value at any point of execution there is no any side effects. State of any variable is constant at any instant. Ex:
x = x + 1 // this changes the value assigned to the variable x.
// so the expression is not referentially transparent.
Functional programming use a declarative approach.
Procedural programming paradigm
Procedural programming is based on procedural call. Also known as procedures, routines, sub-routines, functions, methods. As procedural programming language follows a method of solving problems from the top of the code to the bottom of the code, if a change is required to the program, the developer has to change every line of code that links to the main or the original code. Procedural paradigm provide modularity and code reuse. Use imperative approach and have side effects.

Event driven programming paradigm
It responds to specific kinds of input from users. (User events (Click, drag/drop, key-press,), Schedulers/timers, Sensors, messages, hardware interrupts.) When an event occur asynchronously they placed it to event queue as they arise. Then it remove from programming queue and handle it by main processing loop. Because of that program may produce output or modify the value of a state variable. Not like other paradigms it provide interface to create the program. User must create defined class. JavaScript, Action Script, Visual Basic and Elm are the example for event-driven programming.
Object oriented Programming
Object Oriented Programming is a method of implementation in which programs are organized as a collection of objects which cooperate to solve a problem. In here program is divide in to small sub systems and they are independent unit which contain their own data and functions. Those units can reuse and solve many different programs.
Key features of object oriented concept
Object - Objects are instances of classes, which we can use to store data and perform actions.
Class - A class is a blue print of an object.
Abstraction - Abstraction is the process of removing characteristics from ‘something’ in order to reduce it to a set of essential characteristics that is needed for the particular system.
Encapsulation - Process of grouping related attributes and methods together, giving a name to the unit and providing an interface for outsiders to communicate with the unit
Information Hiding - Hide certain information or implementation decision that are internal to the encapsulation structure
Inheritance - Describes the parent child relationship between two classes.
Polymorphism - Ability of doing something in different ways. In other words it means, one method with multiple implementation, for a certain class of action

Software Runtime Architecture
Languages can be categorized according to the way they are processed and executed.
Compiled Languages
Scripting Languages
Markup Languages
The communication between the application and the OS needs additional components. Depends on the type of the language used to develop the application component. Depends on the type of the language used to develop the application component.

This is how JS code is executed.JavaScript statements that appear between <script> and </script> tags are executed in order of appearance. When more than one script appears in a file, the scripts are executed in the order in which they appear. If a script calls document. Write ( ), any text passed to that method is inserted into the document immediately after the closing </script> tag and is parsed by the HTML parser when the script finishes running. The same rules apply to scripts included from separate files with the src attribute.
To run the system in different levels there are some other tools use in the industry.
Virtual Machine
Containers/Dockers

Virtual Machine
Virtual machine is a hardware or software which enables one computer to behave like another computer system.
Development Tools
"Software development tool is a computer program that software developers use to create, debug, maintain, or otherwise support other programs and applications." (Wikipedia) CASE tools are used throughout the software life cycle.

Feasibility Study - First phase of SDLC. In this phase gain basic understand of the problem and discuss according to solution strategies (Technical feasibility, Economical feasibility, Operational feasibility, Schedule feasibility). And prepare document and submit for management approval
Requirement Analysis - Goal is to find out exactly what the customer needs. First gather requirement through meetings, interviews and discussions. Then documented in Software Requirement Specification (SRC).Use surveying tools, analyzing tools
Design - Make decisions of software, hardware and system architecture. Record this information on Design specification document (DSD). Use modelling tools
Development - A set of developers code the software as per the established design specification, using a chosen programming language .Use Code editors, frameworks, libraries, plugins, compilers
Testing - Ensures that the software requirements are in place and that the software works as expected. If there is any defect find out developers resolve it and create a new version of the software which then repeats the testing phase. Use test automation tools, quality assurance tools.
Development and Maintenance - Once software is error free give it to customer to use. If there is any error resolve them immediately. To development use VMs, containers/ Dockers, servers and for maintenance use bug trackers, analytical tools.
CASE software types
Individual tools
Workbenches
Environments
Frameworks Vs Libraries Vs Plugins

Do you know how the output of an HTML document is rendered?
This is how it happen. When browser receive raw bytes of data it convert into characters. These characters now further parsed in to tokens. The parser understands each string in angle brackets e.g "<html>", "<p>", and understands the set of rules that apply to each of them. After the tokenization is done, the tokens are then converted into nodes. Upon creating these nodes, the nodes are then linked in a tree data structure known as the DOM. The relationship between every node is established in this DOM object. When document contain with css files(css raw data) it also convert to characters, then tokenized , nodes are also formed, and finally, a tree structure is also formed . This tree structure is called CSSOM Now browser contain with DOM and CSSOM independent tree structures. Combination of those 2 we called render tree. Now browser has to calculate the exact size and position of each object on the page with the browser viewpoint (layout ). Then browser print individual node to the screen by using DOM, CSSOM , and exact layout.
JAVA
Java is general purpose programming language. It is class based object oriented and concurrent language. It let application developers to “Write Once Run anywhere “. That means java code can run on all platforms without need of recompilation. Java applications are compiled to bytecode which can run on any JVM.

Do you know should have to edit PATH after installing JDK?
JDK has java compiler which can compile program to give outputs. SYSTEM32 is the place where executables are kept. So it can call any wear. But here you cannot copy your JDK binary to SYSTEM32 , so every time you need to compile a program , you need to put the whole path of JDK or go to the JDK binary to compile , so to cut this clutter , PATH s are made ready , if you set some path in environment variables , then Windows will make sure that any name of executable from that PATH’s folder can be executed from anywhere any time, so the path is used to make ready the JDK all the time , whether you cmd is in C: drive , D: drive or anywhere . Windows will treat it like it is in SYSTEM32 itself.
1 note
·
View note